毫末科技数据库设计规范
作者:毫末科技
邮箱:hxg@haomo-studio.com
1 设计工具
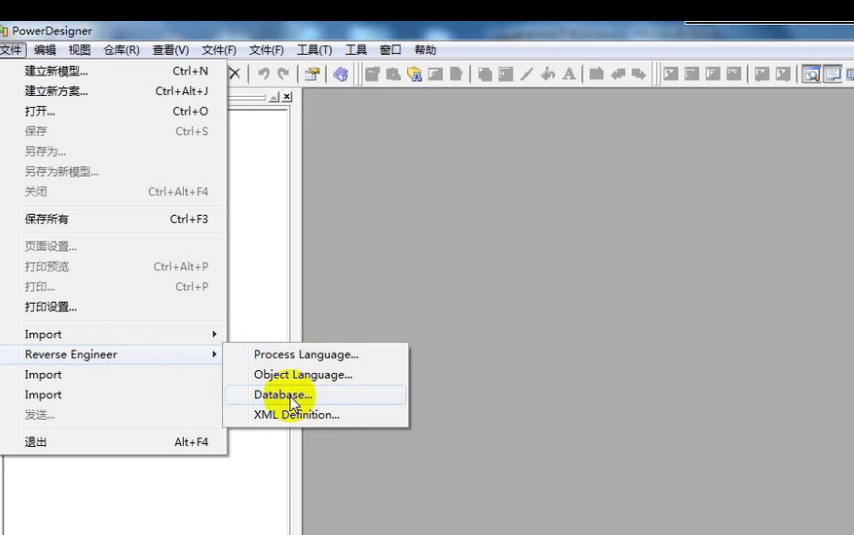
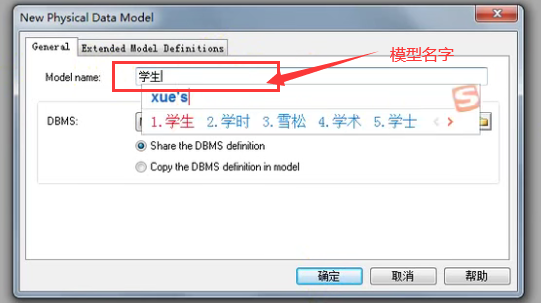
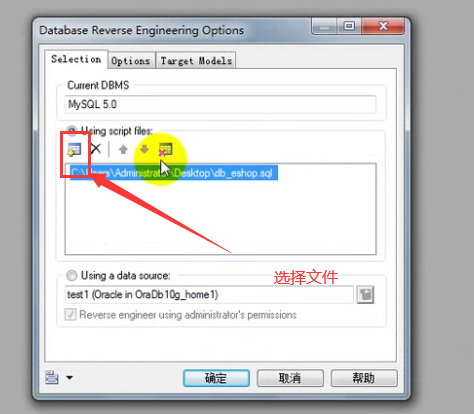
- 公司所有项目的数据库设计必须采用PowerDesigner 16.5进行设计
2 设计规范
必知规范:
- 数据库和表的字符集统一使用 utf8mb4,排序用:utf8mb4_general_ci;
- 所有的表、字段,code必须采用小写英文下划线命名(如 sys_user),原则上不允许采用中文拼音缩写。表的name必须为中文命名;
- 所有表和字段都需要添加注释。使用 comment 从句添加表和列的备注 从一开始就进行数据字典的维护;
- 视图以view_开头,例如:view_depart_user;
- 多对多关联表以 m2m_开头,例如:m2m_author_book;
- 分表以 _00~_99结尾,例如:user_00,user_01;
- 所有的表必须包含以下字段:
- id 主键(INT or VARCHAR )
- create_time 创建时间(datetime)
- create_by 创建人 ( VARCHAR)
- update_time 修改时间 (datetime)
- update_by 修改人(varchar)
- del_flag 删除状态( int)
其他规范:
- 数据库设计时,应该要对以后扩展进行考虑
- 所有表必须使用 InnoDB 存储引擎
- 没有特殊要求(即 InnoDB 无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎(MySQL 5.5 之前默认使用 Myisam,5.6 以后默认的为 InnoDB)InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。(==我们程序中禁止使用事务,因为事务有锁表风险==)
- 尽量控制单表数据量的大小,建议控制在 500 万以内。500 万并不是 MySQL 数据库的限制,过大会造成修改表结构、备份、恢复都会有很大的问题,可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
- 谨慎使用 MySQL 分区表。分区表在物理上表现为多个文件,在逻辑上表现为一个表 谨慎选择分区键,跨分区查询效率可能更低 建议采用物理分表的方式管理大数据。
- 禁止在数据库中存储图片,文件等大的二进制数据。通常文件很大,会短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随机 IO 操作,文件很大时,IO 操作很耗时 通常存储于文件服务器,数据库只存储文件地址信息。
- 禁止在线上做数据库压力测试
- 禁止从开发环境,测试环境直接连接生成环境数据库
- 命名要能做到见名识意,单词之间用下划线分开
- 字段要有明确的注释,描述该字段的用途及可能存储的内容
- 禁止在表中建立预留字段。预留字段的命名很难做到见名识义 预留字段无法确认存储的数据类型,所以无法选择合适的类型 对预留字段类型的修改,会对表进行锁定
- 所有字段,均为非空(NOT NULL),最好显示指定默认值
- 数值类型的字段请使用UNSIGNED属性
- 是别的表的外键均使用xxx_id的方式来表明;
- 所有的布尔值字段,以is_ 前缀,如is_hot、is_deleted,都必须设置一个默认值,并设为0;使用tinyint 类型
- varchar类型字段的程序处理,要验证用户输入,不要超出其预设的长度;
- 不同表中表达同一意思字段要统一,例如创建时间统一 用created_at;更新时间用 updated_at;备注统一用 remark 排序统一用order_id
- 避免使用ENUM 类型的 可以用tinyint 类型代替
- 同财务相关的金额类型使用 decimal 类型
- text字段尽量少用,或是拆到冗余表中
- 禁止给表中的每一列都建立单独的索引,合理使用联合索引,建议索引数量不超过 5 个
- 避免建立冗余索引和重复索引
3 数据库设计原则
- 小既是美:用可以表示要储存的数据的最小值的类型。小的类型可以更快,因为他们会占用更少的磁盘,内存,CPU缓存空间,通常也只需要更少的CPU指令来处理
- 简单:处理简单的数据类型可以使用更少的CPU指令
4 常用字段类型
4.1 MySQL 常用字段类型
- int 用于主键和大部分整数字段取值范围:-2147483648~214748364
- tinyint 用于状态存储,例如(性别,状态)
- varchar 字符串类型用于绝大部分数据(可用于主键)
- decimal 一般用于货币字段,例如decimal(10,2)8位整数,小数点后保留两位
- text 需要存储非常大量的字符串时使用,例如备注等
- datetime 用于存储日期和时间信息
5 数据库设计流程
5.1 需求分析
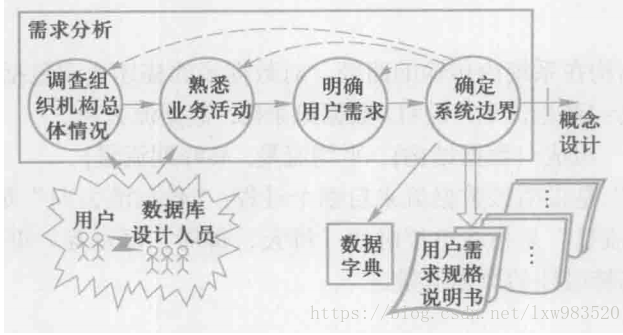
- 需求分析任务
需求分析的任务是通过详细调查现实世界要处理的对象(组织、部门、企业等),充分了解原系统(手工系统或计算机系统)的工作概况,明确用户的各种需求,然后在此基础上确定新系统的功能。新系统必须充分考虑今后可能的扩充和改变,不能仅仅按当前应用需求来设计数据库。 调查的重点是“数据”和“处理”,通过调查、收集与分析,获得用户对数据库的如下要求:
- 信息要求。指用户需求从数据库中获得信息的内容与性质。由信息要求可以导出数据要求,即在数据库中需求存储哪些数据。
- 处理要求。指用户要求完成的数据处理功能,对处理性能的要求。
安全性与完整性要求。
需求分析的方法
调查组织机构情况。
- 调查各部门的业务活动情况。
- 在熟悉业务活动的基础上,协助用户明确对新系统的各种要求,包括信息要求、处理要求、安全性与完整性要求。
- 确定新系统的边界。对前面的调查结果进行初步分析,确定哪些功能由计算机完成或将来准备让计算机完成,哪些活动由人工完成。由计算机完成的功能就是新系统应该实现的功能。
5.2 模型设计
数据模型含义
是对客观事物及其联系的数据描述,即对现实世界(存在于人脑之外的客观世界)的模拟。例:桌子、笔等 在数据库中用数据模型来抽象、表示和处理现实世界中的数据和信息。 要将现实世界转变为机器能够识别的形式,必须经过两次抽象。
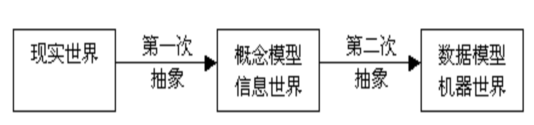
概念模型设计
概念模型,它是按照用户的观点来对信息和数据建模,主要用于数据库设计,最常用的是实体联系模型。
相关概念
实体(Entity):客观存在并可以相互区别的事物。 例如:一个教师、一辆车、老师与学生的关系都是实体。
- 属性(Attribute):实体所具有的特性称为实体的属性,一个实体由它的若干属性来体现。 例如:课程实体由课程编号、课程名称、课程类别等属性组成。
- 码(Key):唯一确定实体的属性集称为码,例如:课程编号是课程实体的码。
- 域(Domain):属性的取值范围称为该属性的域。 假若规定课程编号只能取四位整数,那么这就是课程编号的域,它的范围是1000到9999。
- 实体集(Entity Set):具有相同属性和性质的实体的集合称为实体集。 例如:所有课程就是一个实体集。
- 联系(Relationship):事物内部以及事物之间总是存在着某中联系,这些联系在概念模型中表现为实体内部的联系和实体之间的联系。
实体间的联系分为三类:
一对一的联系(1:1) 如果对于实体集A中的每一个实体,在实体集B中至多有一个实体与它有关联,反之,亦成立,则实体集A与实体集B具有一对一的联系,用1:1表示。 例如:班长实体集与班级实体集是一对一的联系。
一对多的联系(1:n) 如果对于实体集A中的每一个实体,在实体集B中可能有多个实体与它有关联,反之,如果对于实体集B中的每一个实体,在实体集A至多有一个实体与它有关联,则实体集A与实体集B具有一对多的联系,用1:n表示。 例如:班级实体集与学生实体集是一对多的联系。
多对多的联系(m:n) 如果对于实体集A中的每一个实体,在实体集B中可能有多个实体与它有关联,反之,亦成立,则实体集A与实体集B具有一对多的联系,用m:n表示。
ER图的绘制
- 基本要素的表示方法:
长方形——实体
椭 圆——属性
菱 形——联系**
说明:在相应的框内要写上实体名、属性名或联系名。
- 绘制方法:
实体与属性用直线相连
实体与联系用直线相连
联系与属性用直线相连
同时在菱形与矩形的连线上标上联系的类型。
(1:1、1:n、m:n)
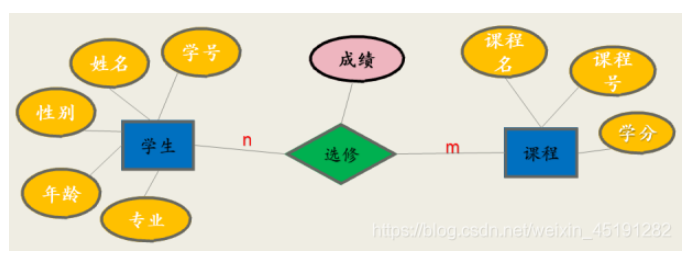
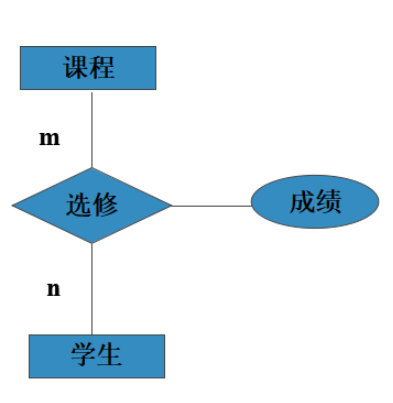
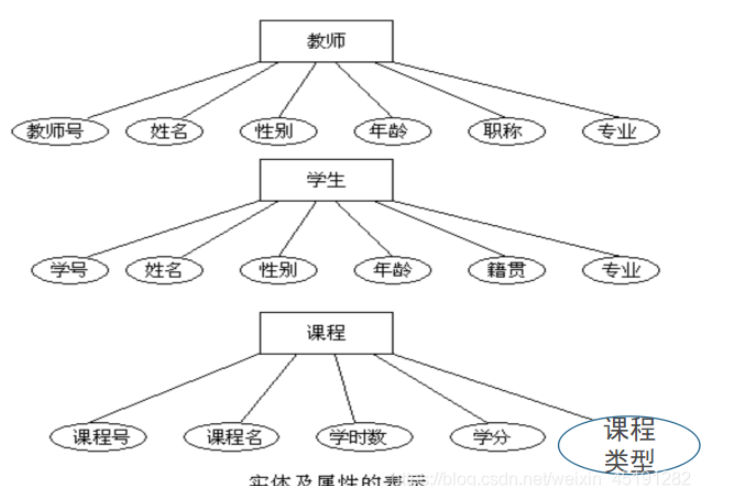
简化ER图
可以先分别画出每一个实体及属性。
然后,再画实体间的联系及联系的属性,并标明实体之间的联系类型
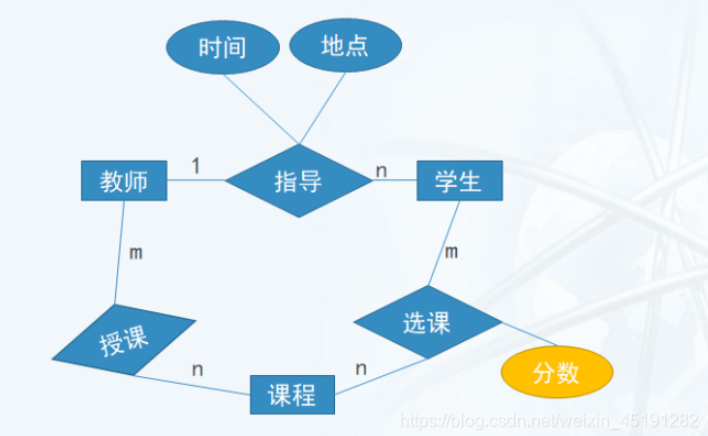
设计原则:先局部,后综合。 设计局部ER图。建立步骤:
- 确定实体类型及属性。
- 确定联系类型及属性。
- 把实体类型和联系类型组合成局部ER图。 综合成全局ER图。合并步骤:
- 合并局部ER图,消除冲突(属性、结构、命名冲突),生成初步ER图。
- 消除初步ER图的数据冗余和联系冗余,生成基本ER图。
设计原则:消除冲突
- 属性冲突属性域冲突,即属性值的类型、取值范围或取值集合不同。例如零件号,有的部门把它定义为整数,有的部门把它定义为字符型。例如年龄,某些部门以出生日期形式表示职工的年龄,而另一些部门用整数表示职工的年龄。属性取值单位冲突。例如,零件的重量有的以公斤为单位,有的以斤为单位,有的以克为单位。
- 命名冲突同名异义,即不同意义的对象在不同的局部应用中具有相同的名字。异名同义(一义多名),即同一意义的对象在不同的局部应用中具有不同的名字。如对科研项目,财务科称为项目,科研处称为课题,生产管理处称为工程。命名冲突可能发生在实体、联系一级上也可能发生在属性一级上通过讨论、协商等行政手段加以解决
- 结构冲突 同一对象在不同应用中具有不同的抽象。 例如,职工在某一局部应用中被当作实体,而在另一局部应用中则被当作属性。 解决方法:把属性变换为实体或把实体变换为属性,使同一对象具有相同的抽象。 同一实体在不同子系统的E-R图中所包含的属性个数和属性排列次序不完全相同。 解决方法:使该实体的属性取各子系统的E-R图中属性的并集,再适当调整属性的次序。
建立步骤:
确定实体类型及属性。
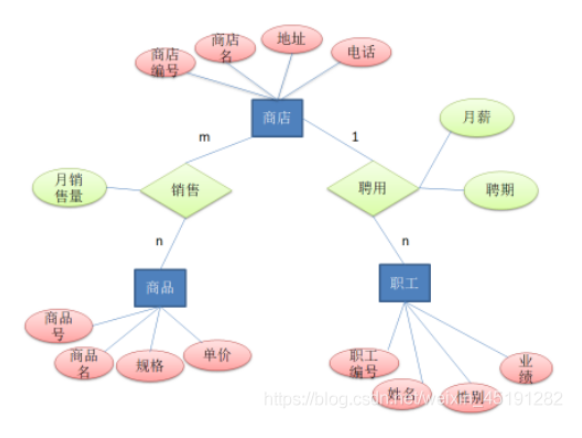
本题已知有:商店、商品、顾客。
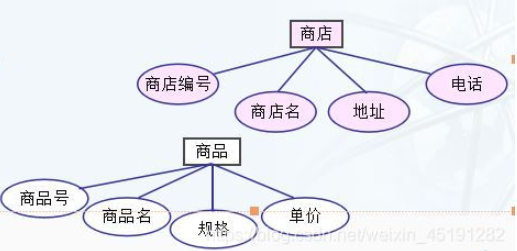
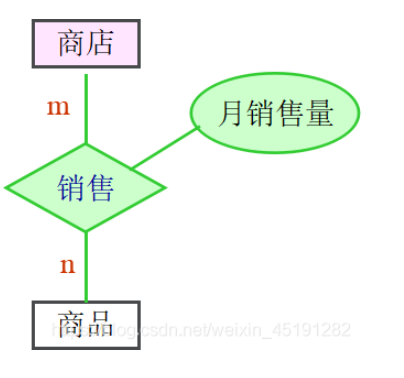
确定联系类型及属性
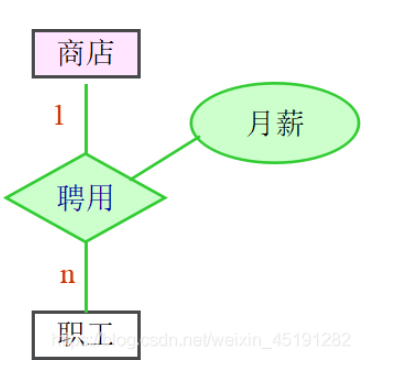
“商店-商品”的联系是m:n 联系的属性有三项: 商店(编号) 商品(编号) 月销售量
联系的名称:销售
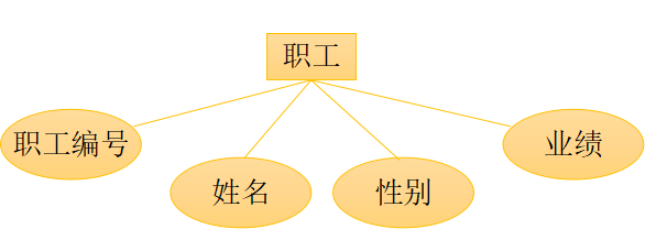
“商店-职工”的联系是m:n 联系的属性有四项: 商店(编号) 职工(编号) 月薪 聘期联系的名称:聘用
把实体类型和联系类型组合成ER图。
5.3 实例
学生成绩管理系统数据库设计
- 需求分析
(1)信息需求
对学校而言,学生成绩管理是管理工作中重要的一环,但是高校学生的成绩管理工作量大、繁杂,人工处理非常困难。因此,借助于强大计算机的处理能力,能够把人从繁重的成绩管理工作中解脱出来,并且更加准确、安全、清晰的管理环境。
(2)功能需求
能够进行数据库的数据定义、数据操纵、数据控制等处理功能。具体功能应包括:可提供课程安排、课程成绩数据的添加、插入、删除、更新、查询,学生及教职工基本信息查询的功能。
(3)安全性与完整性要求
对于学生成绩管理系统数据库来讲,由于其主要数据是学生成绩,只能由本人以及所教老师及教务处知道,因此做好数据安全性是重中之重。另外,要求所有在校学生的信息都要录入其中,并且要设计好个别情况。
- 概念结构设计
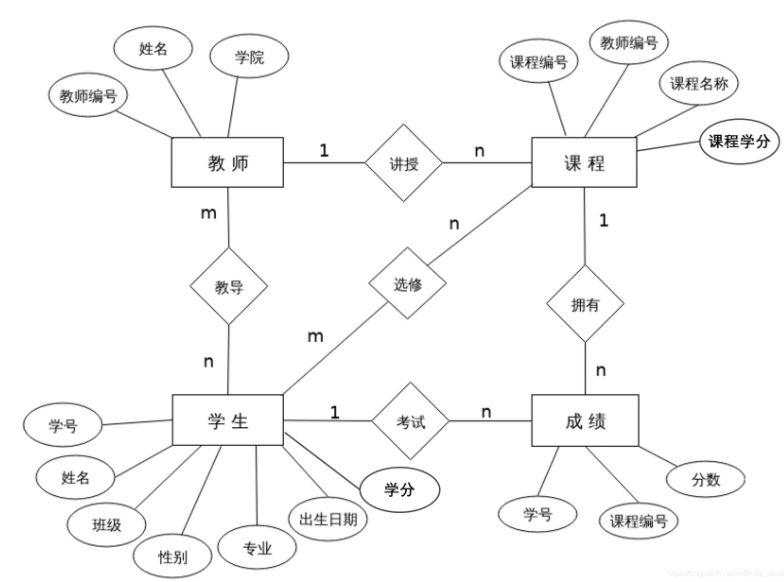
一位学生会被多位老师教导,一位老师会教导多位学生,所有学生与教师之间是多对多的关系;
一位学生可能会选修多门课程,一门课程会被多位学生选修,所以学生与课程之间是多对多的关系;
一位学生会有多项成绩(具体指某学生一门课程的分数),一项成绩仅被一位学生拥有,所以学生与成绩是一对多的关系;
一位教师会讲授多门课程,一门课程会被一位教师讲授,所以教师与课程的关系是一对多的关系;
一门课程拥有多项成绩,一项成绩仅被一门课程拥有,所以课程与成绩的关系是一对多的关系;
- 抽象出系统实体
学生(学号、姓名、班级、性别、专业、出生日期、学分); 老师(教师编号、姓名、学院); 课程(课程编号、教师编号、课程名称、课程学分); 成绩(学号、课程编号、分数);
5.4 powerdesigner使用教程
建立模型

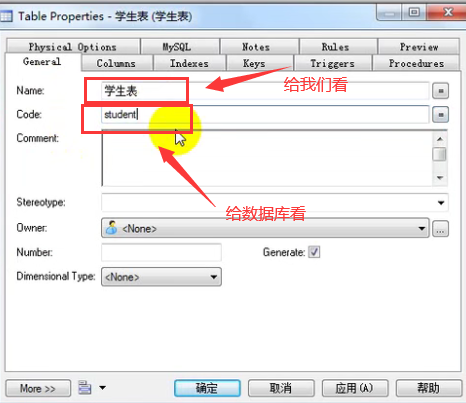
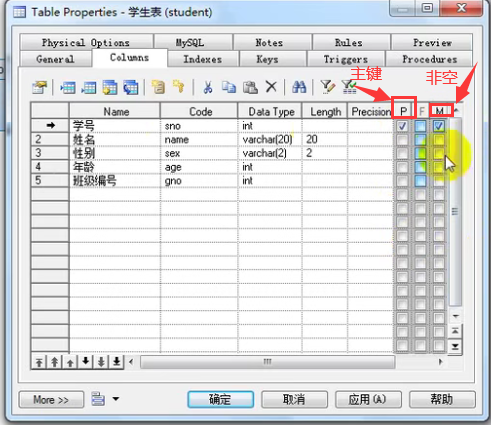
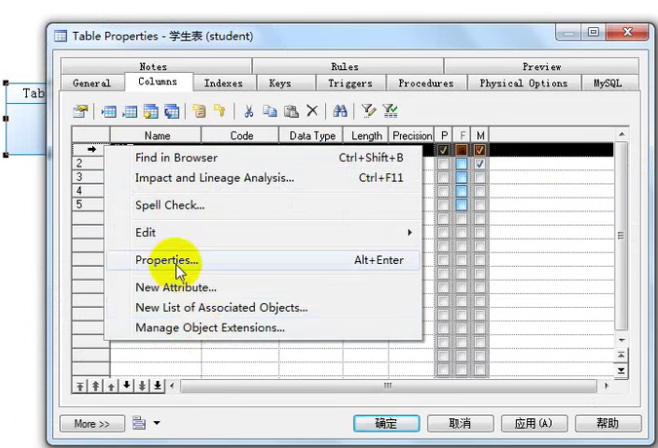
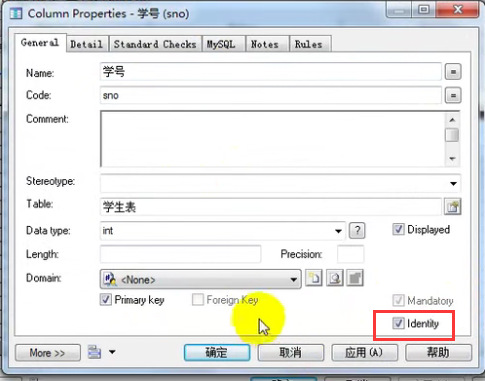
设置主键自增
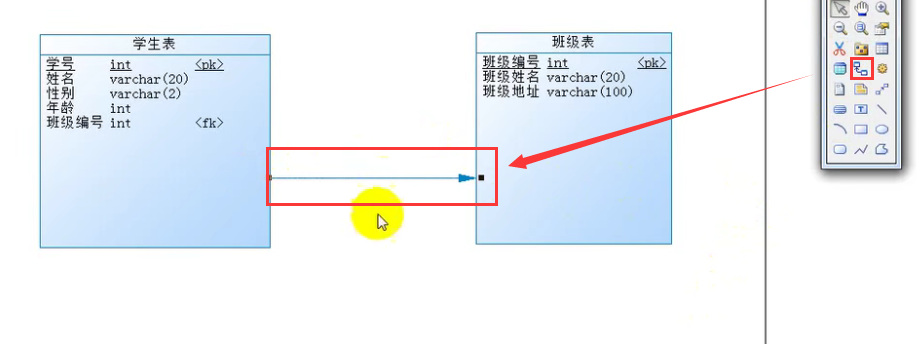
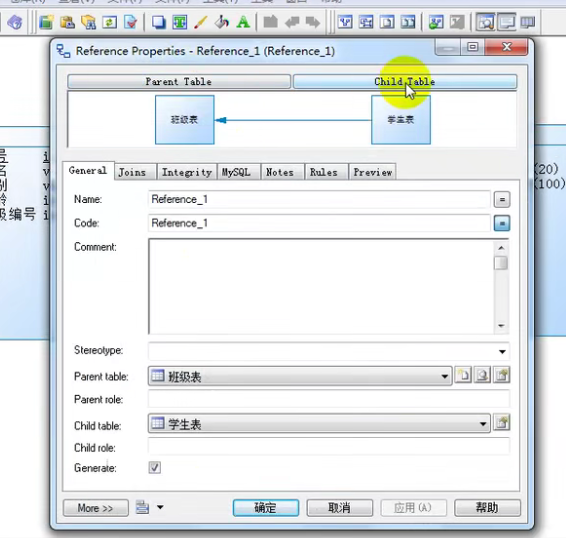
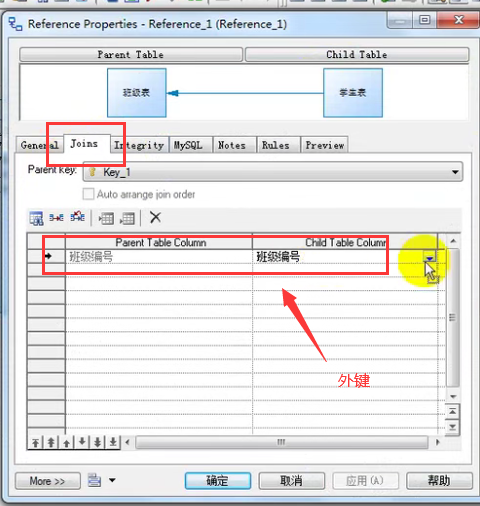
连接表
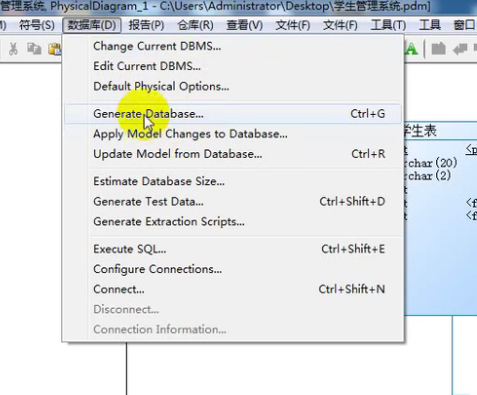
- 导出sql文件
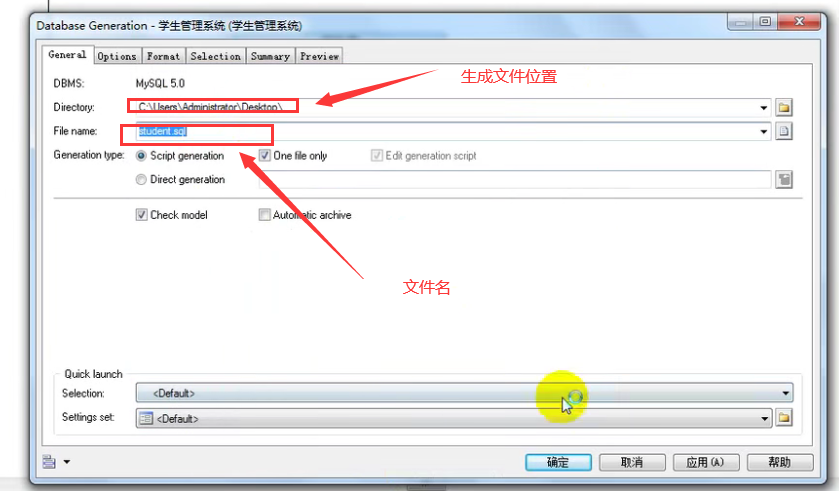
- 导入pdm